# 자바가 제공하는 제어문을 학습하세요.
# 학습할 것
- 선택문
- 반복문
선택문
실행 코드를 제어하는 방법 중 선택문에 대해 정리해보려 한다.
또 다른 말로 조건문 이라고 알고 있는 이 선택문은 크게 if 와 switch 가 있다.
지난주에 switch에 대해 알아보았으니, 이번엔 if에 대해 정리해보려 한다.
구분하기 나름이겠지만 if 문은 크게 세가지 형태가 있다.
1. if (조건) { 실행 블록 }
2. if (조건) { 조건이 참일 때 실행 블록 } else { 조건이 거짓일 때 실행 블록 }
3. if (조건1) { 조건1이 참일 때 실행 블록 } else if (조건2) { 조건2가 참일 때 실행 블록 }
말로 보면 혼란스러우니 코드를 보자.
package me.xxxelppa.study.week04;
public class Exam_001 {
public static void main(String[] args) {
boolean condition_1 = true;
if(condition_1) {
System.out.println("condition_1 이 참 입니다");
}
if(condition_1) System.out.println("condition_1 이 참 입니다");
}
}
| condition_1 이 참 입니다 condition_1 이 참 입니다 |
실행 블록 내의 코드가 한 줄인 경우 중괄호를 생략할 수 있다.
if 조건문의 소괄호 안의 내용은 boolean 으로 (참/거짓) 판별할 수 있는 값이 들어와야 한다.
package me.xxxelppa.study.week04;
public class Exam_002 {
public static void main(String[] args) {
boolean condition_1 = true;
boolean condition_2 = false;
if(condition_1 && condition_2) {
System.out.println("condition_1과 condition_2 모두 참 입니다");
} else {
System.out.println("condition_1과 condition_2 중에 거짓이 있습니다.");
}
if(condition_1 && condition_2) System.out.println("condition_1과 condition_2 모두 참 입니다");
else System.out.println("condition_1과 condition_2 중에 거짓이 있습니다.");
/*
* 심지어 이렇게 작성해도 잘 동작 하지만
* 권장하지 않는 방법.
*/
if(condition_1 && condition_2) {
System.out.println("condition_1과 condition_2 모두 참 입니다");
} else System.out.println("condition_1과 condition_2 중에 거짓이 있습니다.");
}
}
| condition_1과 condition_2 중에 거짓이 있습니다. condition_1과 condition_2 중에 거짓이 있습니다. condition_1과 condition_2 중에 거짓이 있습니다. |
이번엔 두 번째 스타일의 코드를 작성 해보았다.
소괄호 안에 작성한 논리 결과가 참인 경우와 거짓인 경우에 따라 어떤 실행 블록을 처리할지 달라진다.
이번에는 조건이 다양한 경우에 대한 예시이다.
package me.xxxelppa.study.week04;
public class Exam_003 {
public static void main(String[] args) {
int score = 87;
if (score >= 90) {
System.out.println("매우 우수합니다.");
} else if (score >= 80) {
System.out.println("준수합니다.");
} else if (score >= 70) {
System.out.println("노력이 필요합니다.");
} else if (score >= 60) {
System.out.println("많은 노력이 필요합니다.");
} else {
System.out.println("뭔가 잘못 되었습니다.");
}
if (score >= 90) System.out.println("매우 우수합니다.");
else if (score >= 80) System.out.println("준수합니다.");
else if (score >= 70) System.out.println("노력이 필요합니다.");
else if (score >= 60) System.out.println("많은 노력이 필요합니다.");
else System.out.println("뭔가 잘못 되었습니다.");
}
}
| 준수합니다. 준수합니다. |
if 문의 특징은 한 번이라도 조건에 만족하는 경우를 찾으면, 그 다음 조건에 대해서는 생략한다는 것이다.
위의 예시에서 보면 score 값이 87 의 값을 가지기 때문에 60과 같거나 크고, 70과 같거나 크고 또 80과 같거나 크기 때문에
혹시 세 개의 실행 블록을 처리한다고 생각할 수 있지만
가장 먼저 만족하는 조건에 대한 실행 블록만 실행하기 때문에
때에 따라 조건을 확인하는 순서에 유의해서 작성해야 한다.
서로 연관이 없는 경우 else if 로 연결하여 하나의 선택문을 만들지 않고
새로운 if 문장을 실행하여 독립적으로 검사하는 문장을 작성할 수 있다.
이런 경우는 드물겠지만, 굳이 예를 든다면 다음과 같은 예를 들 수 있을것 같다.
package me.xxxelppa.study.week04;
public class Exam_004 {
public static void main(String[] args) {
int point;
int score = 87;
/*
* 검수에 따라 point 를 달리 지급하는 예시
*/
// example 1
point = 0;
if (score >= 90) ++point;
else if (score >= 80) ++point;
else if (score >= 70) ++point;
else if (score >= 60) ++point;
System.out.println("example 1 : " + point);
System.out.println();
// example 2
point = 0;
if (score >= 90) ++point;
if (score >= 80) ++point;
if (score >= 70) ++point;
if (score >= 60) ++point;
System.out.println("example 2 : " + point);
}
}
| example 1 : 1 example 2 : 3 |
마지막으로 if 문 안에 또 다른 if 문을 얼마든지 중복 해서 사용할 수 있다.
하지만 너무 중복 해서 사용하면 가독성이 심하게 떨어질 수 있기 때문에 조심해야 한다.
그리고 실행 블록 { } 을 생략할 수 있다고 하지만 되도록 실행 블록을 작성 하는 것이 일반적으로 가독성이 더 좋다.
반복문
반복문은 어떤 조건이 만족하는 동안 같은 내용을 계속해서 반복하는 문장이다.
종류는 크게 세 가지가 있다.
1. for
2. while
3. do while
세가지 중에서 가장 많이 사용하는 것은 for문이다.
왜냐하면 while 문은 잘못하면 실행 블록이 무한정 반복할 수도 있기 때문이다.
가장 기본적인 for 문은 다음과 같다.
package me.xxxelppa.study.week04;
public class Exam_005 {
public static void main(String[] args) {
for (int i = 0; i < 10; ++i) {
System.out.println(i + " 번째 실행");
}
}
}
| 0 번째 실행 1 번째 실행 2 번째 실행 3 번째 실행 4 번째 실행 5 번째 실행 6 번째 실행 7 번째 실행 8 번째 실행 9 번째 실행 |

for문은 다음과 같은 특징을 갖는다.
1. 초기화식과 조건부, 증감부는 세미콜론 ; 으로 구분한다.
2. 초기화식은 for문이 실행될 때 단 한번만 실행 한다.
3. 조건부가 거짓이면 for문을 더이상 진행하지 않고 종료한다.
4. 조건부가 참이면 실행 블록을 실행하고 증감부를 실행한 다음 다시 한 번 조건부를 실행한다.
이렇게 계속 조건을 확인하면서 실행 블록을 반복 처리하는 것이 for 문이다.
만약 반복문을 사용하지 않고 동일한 결과를 얻기 위해서는 다음과 같이 작성할 수 있다.
package me.xxxelppa.study.week04;
public class Exam_006 {
public static void main(String[] args) {
System.out.println("0 번째 실행");
System.out.println("1 번째 실행");
System.out.println("2 번째 실행");
System.out.println("3 번째 실행");
System.out.println("4 번째 실행");
System.out.println("5 번째 실행");
System.out.println("6 번째 실행");
System.out.println("7 번째 실행");
System.out.println("8 번째 실행");
System.out.println("9 번째 실행");
}
}
지금은 10번 이지만, 100번 1,000번 반복 해야 한다고 하면 끔직한 일이 아닐 수 없다.
처음 for문을 배우면 간혹 틀에 갇혀 암기하는 경우를 많이 보았다.
package me.xxxelppa.study.week04;
public class Exam_007 {
public static void main(String[] args) {
for (int i = 0; i < args.length; ++i) {
}
}
}
for문을 배울 때면 배열에 대해 배운 다음이거나 같이 배우는 경우가 많다.
배열은 1부터 시작하지 않고 0부터 시작한다. (이를 zero base 라고도 한다.)
그래서 '포 인트 아이는 영 에서 [배열]의 길이보다 작은 동안 ++아이' 이렇게 통째로 암기하는 것을 본 적이 있다. (실화다)
for문을 다양하게 활용하기 위해서는 절대 잊지 말아야 하는 것이 있다.
1. 초기화식, 조건문, 증감문을 반드시 작성할 필요는 없다.
2. 초기화식, 조건문, 증감문을 얼마든지 확장해서 구현할 수 있다.
3. 증감문에 반드시 ++/-- (전위 또는 후위 증감 연산자) 같은 연산자를 사용할 필요는 없다.
4. 조건문에 사용하는 변수가 있는 경우, 이 변수가 꼭 초기화식에서 선언한 변수일 필요는 없다.
이것만 기억하고 잘 활용 한다면 다양하고 재미있는? 반복문을 만들 수 있다.
package me.xxxelppa.study.week04;
public class Exam_008 {
public static void main(String[] args) {
/*
* 10부터 100까지 출력하는 예시
*
* 1. 반복문에서 사용 할 index 를 for 문 초기화식 밖에서 선언
* 2. index 값을 1씩 증가하지 않고 10씩 증가
*/
int index;
for (index = 10; index <= 100; index += 10) {
System.out.println("index : " + index);
}
// index 를 for문 밖에 선언 했기 때문에 for 문 종료 이후 참고하여 사용할 수 있다.
System.out.println("최종 index : " + index);
}
}
| index : 10 index : 20 index : 30 index : 40 index : 50 index : 60 index : 70 index : 80 index : 90 index : 100 최종 index : 110 |
최종 index가 100이 아닌 110이 나온 이유는 굳이 설명하지 않아도 for문의 실행 순서를 기억한다면 알 수 있다.
또는 다음과 같은 것도 가능하다.
package me.xxxelppa.study.week04;
public class Exam_009 {
public static void main(String[] args) {
for(int i = 0, j = 10; i != j; ++i, --j) {
System.out.println(i + " :: "+ j);
}
}
}
| 0 :: 10 1 :: 9 2 :: 8 3 :: 7 4 :: 6 |
초기화식에 하나가 아닌 두 개의 변수를 선언했고, 증감부에서 각 변수에 대한 조작을 넣었다.
증감부를 생략 할 수 있기 때문에 다음과 같이 작성해도 동일한 결과를 받아볼 수 있다.
package me.xxxelppa.study.week04;
public class Exam_010 {
public static void main(String[] args) {
for(int i = 0, j = 10; i != j; ) {
System.out.println(i + " :: "+ j);
++i;
--j;
}
}
}
초기화식 부분도 생략할 수 있기 때문에 다음과 같이 작성해볼 수도 있다.
package me.xxxelppa.study.week04;
public class Exam_011 {
public static void main(String[] args) {
int i = 0, j = 10;
for(; i != j;) {
System.out.println(i + " :: "+ j);
++i;
--j;
}
}
}
생략이 가능하지만, 주의할 점은 이를 구분하는 세미콜론은 생략하면 안된다는 것이다.
반복문을 활용하는 방법이 무궁무진하기 때문에 사용하기 나름이라고 밖에 할 수 없을 것 같다.
** 심지어 다음과 같이 작성해도 잘 동작 한다.
package me.xxxelppa.study.week04;
public class Exam_021 {
public static void main(String[] args) {
System.out.println("================================= 피보나치 수열 =================================");
for(int cnt = 0, bf = 0, af = 1; cnt++ < 30; System.out.print(cnt == 1 ? "1\t" : (af += bf) + (cnt % 10 == 0 ? "\n" : "\t")), bf = cnt == 1 ? bf : af - bf);
}
}

더 다양하고 비범하게 사용할 수 있겠지만 과도한 응용은 정신 건강에 해로울 수 있으니 적절하게..
for문에 대한 마지막으로, '향상된 for문' (또는 개선된 for문) 이라고 불리는 문법이 있다.
반복문과 배열을 같이 사용하는 경우가 많기 때문에, 배열을 예시로 들어보자.
만약 반복 처리의 대상이 배열의 모든 요소라면 다음과 같이 작성해볼 수 있다.
package me.xxxelppa.study.week04;
public class Exam_012 {
public static void main(String[] args) {
int[] myArray = new int[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int sum = 0;
/*
* for 문 역시 실행 블록이 한 줄이라면 블록 { }을 생략할 수 있다.
*/
for (int i = 0; i < myArray.length; ++i) sum += myArray[i];
System.out.println("총합 : " + sum);
}
}
이것을 향상된 for문으로 고치면 다음과 같이 할 수 있다.
package me.xxxelppa.study.week04;
public class Exam_013 {
public static void main(String[] args) {
int[] myArray = new int[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int sum = 0;
/*
* for 문 역시 실행 블록이 한 줄이라면 블록 { }을 생략할 수 있다.
*/
for (int elem : myArray) sum += elem;
System.out.println("총합 : " + sum);
}
}
이 부분에 대해 호기심이 생겨 바이트 코드를 열어보기로 했다.

너무 작아서 잘 안보이겠지만
색칠 된 부분이 서로 다른 부분이다.
바이트코드의 op코드가 향상된 for 문으로 작성했을 때 조금 더 많아 성능 차이가 있을 수도 있겠다고 생각했다.
그래서 호기심이 생겨 여러가지 테스트를 해보았는데, 성능 차이를 느낄 수 없었다.
마지막으로 for 문에 대한 작은 팁? 이라면 팁이고 주의해야 한다면 주의해야 할 부분이 하나 있다.
그것은 조건부 영역에서 배열이나 collection 계열의 자료구조를 사용할 때 크기를 가지고 판단하는 경우가 많다.
package me.xxxelppa.study.week04;
import java.util.ArrayList;
import java.util.List;
public class Exam_014 {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
int sum;
/*
* 테스트하기 위한 선행 작업
* 픽스처 (fixture) 라고도 한다.
*/
for(int i = 0; i < 100; ++i) list.add(i);
/*
* size 를 사용했을 때와 사용하지 않았을 때 실행 시간을 비교해 본다.
*/
// 1. 조건부에 size 를 사용했을 경우
long case_1_start_time = System.nanoTime();
sum = 0;
for (int i = 0; i < list.size(); ++i) {
sum += list.get(i);
}
long case_1_end_time = System.nanoTime();
System.out.println("case 1 :: " + (case_1_end_time - case_1_start_time));
// 2. 조건부에 미리 구해둔 size 를 사용했을 경우
long case_2_start_time = System.nanoTime();
sum = 0;
int size = list.size();
for (int i = 0; i < size; ++i) {
sum += list.get(i);
}
long case_2_end_time = System.nanoTime();
System.out.println("case 2 :: " + (case_2_end_time - case_2_start_time));
}
}
| case 1 :: 27300 case 2 :: 16000 |
case 1 은 조건부에서 list 의 size() 를 확인해서 더 반복할지 판단하도록 구현했고
case 2 는 조건부에서 미리 구한 size 를 확인해서 더 반복할지 판단하도록 구현했다.
list 의 크기가 100정도 뿐인데 (단위가 ns 이지만) 차이를 보이고 있다.
어떻게 보면 작은 차이지만 크기가 커지면 성능에 무시할 수 없는 영향을 줄 수 있다.
하지만 때에 따라서 반복문 내에서 list 의 크기를 조작하여
매번 최신의 크기를 확인해야 할 경우도 있을 수 있으니 상황에 맞게 의도한 대로 동작 하도록 잘 구현 해야 한다.
다음으로 while 반복문의 기본적인 생김새를 알아보자.
package me.xxxelppa.study.week04;
public class Exam_015 {
public static void main(String[] args) {
int loopCnt = 10;
int execCnt = 0;
while(execCnt < loopCnt) {
System.out.println("현재 " + ++execCnt + "번째 반복 중입니다.");
}
System.out.println();
execCnt = 0;
while(execCnt < loopCnt) System.out.println("현재 " + ++execCnt + "번째 반복 중입니다.");
}
}
| 현재 1번째 반복 중입니다. 현재 2번째 반복 중입니다. 현재 3번째 반복 중입니다. 현재 4번째 반복 중입니다. 현재 5번째 반복 중입니다. 현재 6번째 반복 중입니다. 현재 7번째 반복 중입니다. 현재 8번째 반복 중입니다. 현재 9번째 반복 중입니다. 현재 10번째 반복 중입니다. 현재 1번째 반복 중입니다. 현재 2번째 반복 중입니다. 현재 3번째 반복 중입니다. 현재 4번째 반복 중입니다. 현재 5번째 반복 중입니다. 현재 6번째 반복 중입니다. 현재 7번째 반복 중입니다. 현재 8번째 반복 중입니다. 현재 9번째 반복 중입니다. 현재 10번째 반복 중입니다. |
while 조건문은 바로 옆의 소괄호 안에 조건부가 들어간다.
조건부에는 bool 타입 결과를 반환할 수 있어야 하며, 이 값이 참인 동안 실행 블록 { } 의 내용을 반복 한다.
for 문과 달리 소괄호를 공백으로 둘 수 없다.
앞서 for 문에서 정리하지 못했지만, 만약 의도적으로 무한히 반복하는 반복문을 정의하고 싶다면 간단하게 다음과 같이 할 수 있다.
package me.xxxelppa.study.week04;
public class Exam_016 {
public static void main(String[] args) {
/*
* for 문의 무한 반복 처리
*/
for( ; ; ) {
// 이 실행 블록을 무한히 반복한다.
}
/*
* while 문의 무한 반복 처리
*/
while (true) {
// 이 실행 블록을 무한히 반복한다.
}
}
}
(위와 같이 작성하면 IDE에 따라 다를 수 있지만, 8라인의 for 문이 무한반복하는 것을 감지하고
15라인에 실행이 도달할 수 없음을 알려주는 오류가 발생할 수 있다.)

for 문에 비해 while 문을 사용할 때 유난히 무한루프 (무한반복) 상태에 빠지도록 작성 할 가능성이 높다.
개인적으로 while 문 보다는 for 문을 더 많이 사용하는 편이다.
반복문이 무한히 실행되는 경우 작성하는 방법에 대해 알아 보았다.
과연 그런 경우가 얼마나 있을까?
당장 생각나는 경우는 채팅 프로그램이다.
채팅 프로그램 같은 경우 나와 상대방이 존재하고, 상대방이 전달하는 메시지를 내 화면에 출력해 주어야 하기 때문인데
언제 상대방의 메시지가 전달되어 올 지 알 수 없기 때문에 항상 대기 상태를 유지하기 위해 의도적으로 무한루프를 사용할 수 있다.
그럼 이런 프로그램은 강제로 종료해야만 끝이 나는데 과연 좋은 방법일까.
그래서 반복문에서 사용할 수 있는 두 가지 키워드가 존재한다.
하나는 break 이고 다른 하나는 continue 이다.
우선 break 의 사용부터 알아보자.
break 는 단어가 주는 느낌 그대로 반복을 종료하고 싶을 때 사용할 수 있다.
package me.xxxelppa.study.week04;
public class Exam_017 {
public static void main(String[] args) {
//사용자가 입력한 값이라고 가정한다.
int userInput = 10;
System.out.println(getSum(userInput));
}
public static int getSum(int target) {
int result = 0;
int adder = 1;
for(;;) {
if(adder > target) break;
result += adder++;
}
return result;
}
}
| 55 |
17라인에서 의도적으로 무한루프를 발생 시켰다.
그리고 18라인에서 adder 값이 target 보다 크다고 판단이 되면 (즉, 조건이 참인 경우) break 를 실행한다.
이 키워드는 현재 가장 가까운 반복문을 종료한다고 생각하면 된다.
현재 가장 가까운 반복문은 17라인에 정의 되어있으므로 adder가 11이 된 다음 반복문을 탈출 (종료)하고 result 를 반환한다.
while 문에서도 동일하다.
package me.xxxelppa.study.week04;
public class Exam_018 {
public static void main(String[] args) {
//사용자가 입력한 값이라고 가정한다.
int userInput = 10;
System.out.println(getSum(userInput));
}
public static int getSum(int target) {
int result = 0;
int adder = 1;
while (true) {
if (adder > target) break;
result += adder++;
}
return result;
}
}
| 55 |
주의할 것은 반복문을 중첩해서 사용했을 경우, 실행 블록을 혼동하면 의도와는 전혀 다르게 동작할 수 있다.
조금이라도 예방 할 수 있는 방법은 들여쓰기 (indent)를 잘하고, 실행 블록 { } 을 잘 작성해 주는 것 뿐이다.
그럼 break 말고 continue 는 무엇을 하는 키워드 일까.
이 키워드를 만나면 for 문의 경우 증감부를 거쳐 조건부로 바로 이동하고, while 문의 경우 조건부로 바로 이동한다.
위에 작성한 예제와 동일한데, 짝수인 경우만 더하고 싶다면 다음과 같이 할 수 있다.
package me.xxxelppa.study.week04;
public class Exam_019 {
public static void main(String[] args) {
//사용자가 입력한 값이라고 가정한다.
int userInput = 10;
System.out.println(getSum(userInput));
}
public static int getSum(int target) {
int result = 0;
for(int adder = 1; adder <= target; ++adder) {
if(adder % 2 != 0) continue;
result += adder;
}
return result;
}
}
1부터 10까지의 합 중에서 짝수인 경우에만 더해서 반환 하도록 작성한 코드이다.
17라인에서 나머지 연산자를 사용해 2로 나눈 값이 0이 아니라면 홀수임을 뜻하므로
continue 를 만나 다음 실행 블록을 더이상 진행하지 않고 16라인의 증감부로 바로 이동한다.
while 문에서 continue의 의미는 동일하므로 예제를 생략한다.
마지막으로 do while 문이다.
do while 문은 while 문을 알면 쉽게 이해할 수 있다.
기본적인 사용 방법은 다음과 같다.
package me.xxxelppa.study.week04;
public class Exam_020 {
public static void main(String[] args) {
do {
System.out.println("while 반복문의 실행 조건이 false 로 판별 되어도");
System.out.println("do 블록을 무조건 한 번은 실행 합니다.");
} while (false);
}
}
| while 반복문의 실행 조건이 false 로 판별 되어도 do 블록을 무조건 한 번은 실행 합니다. |
while 문의 조건부를 확인하는 것처럼 똑같이 동작 하지만, 차이가 있다면 while 의 조건이 참/거짓 여부에 상관없이
무조건 한 번은 실행해야 하는 내용이 있을 경우 사용할 수 있는 반복문이다.
그 외의 모든 내용은 (break, continue 등) 모두 동일하게 적용 된다.
과제1 : live-study 대시 보드를 만드는 코드를 작성하세요.
- 깃헙 이슈 1번부터 18번까지 댓글을 순회하며 댓글을 남긴 사용자를 체크 할 것.
- 참여율을 계산하세요. 총 18회에 중에 몇 %를 참여했는지 소숫점 두자리가지 보여줄 것.
- Github 자바 라이브러리를 사용하면 편리합니다.
- 깃헙 API를 익명으로 호출하는데 제한이 있기 때문에 본인의 깃헙 프로젝트에 이슈를 만들고 테스트를 하시면 더 자주 테스트할 수 있습니다.
남겨주신 링크를 통해 라이브러리를 사용 해봤다.

링크를 클릭하니 위와 같은 사이트가 열렸다.

최근 버전 중에 사용자가 많은 버전을 사용해보기로 했다.

예제 코드를 작성하는 프로젝트가 maven을 사용하고 있지 않기 때문에, 정보만 참고 했다.

IDE 설정에 보니 maven 저장소에서 jar를 바로 내려받을 수 있는 기능이 있었다.


작업이 끝나면 위와 같이 외부 라이브러리에 추가된 것을 확인할 수 있다.

그리고 나서 샘플 코드를 작성 해보았더니 오류가 발생했다.
사진으로는 잘 안보이지만 읽어보니 제발 personal access token 을 만들어 달라는 간곡한 부탁과 함께
관련된 문서를 볼 수 있는 링크가 있었다. (친절하기도 하셔라)
링크에 들어가면 github 에서 personal access token을 생성하는 방법이 아주 친절하게 나와있다.
github api for Java 링크에서 나와있던 방법 중, To connect via Personal access token 방법을 사용했다.
package me.xxxelppa.study.week04;
import org.kohsuke.github.*;
import java.io.IOException;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
public class Homework_001 {
private static final int ISSUE_COUNT = 18;
public static void main(String[] args) throws IOException {
GitHub github = new GitHubBuilder().withOAuthToken("my_personal_token").build(); // 직접 생성한 토큰사용
GHRepository repository = github.getRepository("nimkoes/live-study").getSource();
GHIssue issue;
List<GHIssueComment> comments;
HashSet<String> hs;
HashMap<String, Integer> hm = new HashMap<>();
for (int i = 1; i <= ISSUE_COUNT; ++i) {
issue = repository.getIssue(i);
comments = issue.getComments();
hs = new HashSet<>();
String name = "";
int size = comments.size();
for (int j = 0; j < size; ++j) {
try {
name = comments.get(j).getUser().getName();
if(name != null && !hs.contains(name)) hm.put(name, hm.getOrDefault(name, 0) + 1);
} catch (IOException e) {
System.out.println("작업 도중 오류가 발생 하였습니다. [" + i + " 주차, 이름 = " + name + "]");
}
}
}
System.out.println("========== 참여율 ==========");
hm.forEach((s, i) -> System.out.printf("%-20s -> %.2f%%\n", s, (i / (float)ISSUE_COUNT * 100)));
}
}
이 방법이 맞는지 모르겠지만.. 실행 결과 일부를 첨부하면 다음과 같다.

되도록 텍스트로 가져오려 했지만, 공백 때문인지 여백이 들쭉날쭉해져서 위쪽 몇 개만 캡처 했다.
전문을 다 가져오는게 큰 의미가 없을 거라 생각했다.
github 사용이 서툴어서 어떻게 하면 좋을지 고민 했는데, 운이 좋게도 내 저장소에 fork 한 다음
15라인 처럼 .getSource() 메소드를 사용하니 원본(?) 저장소에 접근이 가능했다.
처음에 그냥 했을 때는 댓글을 여러 번 남긴 경우가 있었는지, 4 이상의 값을 출력하기도 해서
동일 주차에 댓글이 2개 이상이면 무시하도록 했다. (25라인, 31라인)
그리고 댓글을 달았는지 여부로 참여율만 구하는 것이 목적이기 때문에, 굳이 주차 별 참여 여부에 대한 내용은 고려하지 않았다.
전체 issue의 개수를 가져오고 싶었는데, open 된 상태의 issue만 가져올 수 있는 것 같아서 고민하다가
나는 이미 18주차까지 있다는 것을 알고 있기 때문에 깊게 고민하지 않고 final 변수를 사용했다.
과제2 : LinkedList를 구현하세요.
- LinkedList에 대해 공부하세요.
- 정수를 저장하는 ListNode 클래스를 구현하세요.
- ListNode add(ListNode head, ListNode nodeToAdd, int position)를 구현하세요.
- ListNode remove(ListNode head, int positionToRemove)를 구현하세요.
- boolean contains(ListNode head, ListNode nodeTocheck)를 구현하세요.
List 계열 자료구조의 특징은 순서를 가진다는 것이다.
그 중에 LinkedList 는 리스트(목록)를 구성하는 각 노드(원소 또는 요소)가 링크를 사용하여 연결되어 있는 자료 구조이다.
예를 들면 다음과 같이 생겼다고 상상할 수 있다.

리스트를 구성할 때 크게 배열을 사용하는 방법과 링크를 사용하는 방법이 있다.
배열 구조를 사용했을 때와 링크를 사용했을 때의 장단이 있기 때문에 무엇이 더 좋다고 하기는 어렵다.
그저 현재 해결하려는 문제 상황에 적절한 자료구조를 선택해서 사용하면 될 것 같다.
(예를 들면 검색(탐색)이 빈번하게 발생 하는지, 갱신(입력, 수정, 삭제)이 빈번하게 발생하는지 등)
현재 과제에서 구현해야 하는 기능에 초점을 맞춰 LinkedList 에서 데이터 추가 삭제 및 검색이 어떻게 이루어 지는지 알아보자.
기본적으로 데이터가 위 그림처럼 링크로 연결된 형태로 저장되어 있다고 할 때
임의의 위치에 데이터의 삽입은 다음과 같은 과정을 거쳐야 한다

삽입하고자 하는 위치를 가리키는 값을 복사 한다.
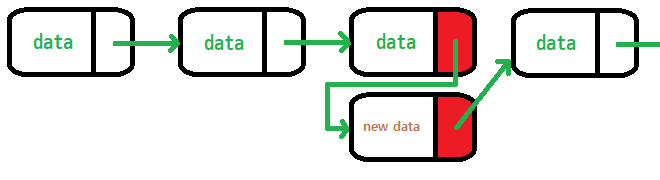
새로 삽입한 데이터를 포함할 수 있도록 다음 노드 값을 바꿔준다.
삭제는 조금 더 간단하다.

삭제 대상이 가리키고 있는 다음 노드에 대한 정보를
자신을 가리키고 있는 노드의 다음 대상으로 넣어주면 된다.
그리고 삭제 대상이 null 참조를 하게 하면 삭제가 완료 된다.
이 문제 상황을 잘 이해하지 못한 것인지 의심이 들지만..
head 역할을 하는 ListNode 가 있고 여기에 값과 다음 노드를 가리킬 값이 있어야 할 것 같은데..
그러니까 다음과 같이 되어야 하는 것 아닌지 생각이 들었다.

그런데 문제의 add 와 remove 메소드 시그니처를 보면 추가하고 삭제하는데 ListNode 를 사용한다.
그래서 어쨌든 ListNode는 int 타입의 값을 담을 변수와 다음 노드를 가리키는 ListNode 타입의 변수를 가지고 있어야 한다.
또한 linear 하게 연결 되어 있지만, 중간에 삽입된 노드를 head 를 통하지 않고 직접 접근이 가능하다면
그 위치를 새로운 head 로 인식하여 추가 삭제 작업이 가능할 수 있다.
지금 다시 생각해보니, 당면한 문제는 길이 0인 리스트를 만들 수 없는 형태로 구현 했다는 것이다.
데이터 범위도 정수이기 때문에 특정 정수 값을 (예를 들면 -1) head 노드라고 판단하도록 사용할 수도 없다.
여러 고민 끝에 다음과 같이 다시 구현 하였다.
package me.xxxelppa.study.week04;
import java.util.Objects;
public class ListNode {
private int data;
private ListNode next;
private boolean isHead;
public int getData() {
return this.data;
}
/*
* 기본 생성자를 사용할 경우 head 노드 생성
*/
public ListNode() {
this.data = 0;
this.next = null;
this.isHead = true;
}
/*
* 생성자에 데이터가 넘어오면 데이터 노드 생성
*/
public ListNode(int data) {
this.data = data;
this.next = null;
this.isHead = false;
}
/*
* 크기를 반환하는 메소드
*/
public int size() {
if(!this.isHead) {
System.out.println("head 노드가 아니므로 길이를 반환할 수 없습니다.");
return -1;
}
int size = 0;
ListNode ln = this;
while(ln.next != null) {
++size;
ln = ln.next;
}
return size;
}
/*
* 입력 받은 position 에 따라 후속 작업이 가능한지 검사
* 1. head 노드가 아닌 경우 false 반환
* 2. position 이 음수인 경우 false 반환
* 3. position 이 현재 리스트의 전체 길이를 넘길 경우 false 반환
*/
private boolean basicValidation(int pos) {
if(!this.isHead) {
System.out.println("head 노드를 기준으로만 처리할 수 있습니다.");
return false;
}
if(pos < 0) {
System.out.println("음수 위치에서 값을 처리할 수 없습니다.");
return false;
}
if(size() < pos) {
System.out.println("현재 리스트 길이보다 큰 위치에서 처리할 수 없습니다.");
return false;
}
return true;
}
/*
* 요소를 추가하는 add 메소드
* null 을 반환하면 추가할 수 없음을 의미
* 성공적으로 추가 해을 경우 추가한 노드를 반환
*/
public ListNode add(ListNode head, ListNode nodeToAdd, int position) {
if(!basicValidation(position)) {
return null;
}
while(--position >= 0) {
head = head.next;
}
nodeToAdd.next = head.next;
head.next = nodeToAdd;
return nodeToAdd;
}
/*
* 특정 위치의 노드를 삭제
* null을 반환하면 삭제할 수 없음을 의미
* 성공적으로 삭제한 경우 삭제한 노드를 반환
*/
public ListNode remove(ListNode head, int positionToRemove) {
if(!basicValidation(positionToRemove)) {
return null;
}
if(size() == 0) {
System.out.println("데이터가 없습니다.");
return null;
}
ListNode deleteNode = head.next, beforeNode = head;
while(--positionToRemove > 0) {
beforeNode = deleteNode;
deleteNode = deleteNode.next;
}
beforeNode.next = deleteNode.next;
return deleteNode;
}
/*
* 노드가 포함되어 있는지 확인
*/
public boolean contains(ListNode head, ListNode nodeTocheck) {
boolean result = false;
if(!head.isHead) {
System.out.println("head 노드가 아니면 작업을 처리할 수 없습니다.");
return result;
}
do {
if(head.equals(nodeTocheck)) {
result = true;
break;
}
head = head.next;
} while(head != null);
return result;
}
@Override
public boolean equals(Object o) {
if(this == o) return true;
if(o == null || getClass() != o.getClass()) return false;
ListNode listNode = (ListNode) o;
return this.data == listNode.data && Objects.equals(this.next, listNode.next);
}
}
간단한 테스트 코드도 작성 해보았다.
package me.xxxelppa.study.week04;
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.*;
class ListNodeTest {
@Test
public void addTest() {
ListNode headNode = new ListNode();
ListNode dataNode = new ListNode(10);
ListNode newDataNode = new ListNode(20);
// head 노드를 참조하지 않으면 데이터 추가를 할 수 없고 시도할 경우 null 을 반환
assertNull(dataNode.add(dataNode, new ListNode(20), 0));
// head 노드를 참조하면 데이터를 추가할 수 있음
assertNotNull(headNode.add(headNode, dataNode, 0));
// head 노드에 데이터 노드가 성공적으로 추가되면 추가한 노드를 반환
assertEquals(newDataNode, headNode.add(headNode, newDataNode, 1));
// 범위 밖의 위치에 값 추가 시도시 null 반환
assertNull(headNode.add(headNode, new ListNode(40), 4));
assertNull(headNode.add(headNode, new ListNode(40), -1));
}
@Test
public void removeTest() {
ListNode headNode = new ListNode();
// 삭제 할 데이터 세팅
for(int i = 1; i < 5; ++i) {
headNode.add(headNode, new ListNode(i * 10), (i-1));
}
// 성공적으로 노드를 삭제하면, 삭제된 노드를 반환
assertEquals(20, headNode.remove(headNode, 2).getData());
// 범위 밖의 위치 노드 삭제 시도시 null 반환
assertNull(headNode.remove(headNode, 4));
assertNull(headNode.remove(headNode, -1));
}
@Test
public void containsTest() {
ListNode headNode = new ListNode();
ListNode containCheckNode = new ListNode(40);
headNode.add(headNode, new ListNode(10), 0);
headNode.add(headNode, new ListNode(20), 1);
headNode.add(headNode, new ListNode(30), 2);
headNode.add(headNode, containCheckNode, 3);
assertTrue(headNode.contains(headNode, containCheckNode));
assertFalse(headNode.contains(headNode, new ListNode(99)));
}
}

과제3 : Stack을 구현하세요.
- int 배열을 사용해서 정수를 저장하는 Stack을 구현하세요.
- void push(int data)를 구현하세요.
- int pop()을 구현하세요.
Stack은 FILO (First In Last Out) 으로 동작하는 자료구조이다.
하노이의 탑을 떠올리면 된다.
package me.xxxelppa.study.week04;
class MyStack {
int[] myStack;
int stackSize;
int dataCount;
public MyStack(int data) {
this.stackSize = 10;
this.dataCount = 1;
this.myStack = new int[stackSize];
this.myStack[0] = data;
}
public void push(int data) {
// 스택 크기를 초과할 경우 10씩 늘려준다.
if(this.stackSize == this.dataCount + 1) {
int[] newStack = new int[stackSize + 10];
for (int i = 0; i < stackSize; ++i) newStack[i] = this.myStack[i];
stackSize += 10;
this.myStack = newStack;
}
this.myStack[this.dataCount++] = data;
}
public int pop() {
if (this.dataCount == 0) {
System.out.println("더 이상 데이터가 없습니다");
return -1;
}
return myStack[--this.dataCount];
}
public void print() {
for (int i = 0; i < this.dataCount; ++i) {
System.out.println(i + " :: " + myStack[i]);
}
}
}
확인해보기 위한 테스트 코드.
package me.xxxelppa.study.week04;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.*;
class MyStackTest {
MyStack myStack;
@BeforeEach
public void before() {
myStack = new MyStack(10);
for (int i = 20; i < 100; i += 10) myStack.push(i);
}
@Test
public void pushTest() {
// 범위를 초과해서 값을 넣어도 오류가 발생하지 않는다.
assertDoesNotThrow(() -> myStack.push(999));
assertDoesNotThrow(() -> myStack.push(888));
assertDoesNotThrow(() -> myStack.push(777));
assertDoesNotThrow(() -> myStack.push(666));
}
@Test
public void popTest() {
// 스택의 모든 값을 꺼내서 확인
for (int i = 90; i > 0; i -= 10) {
assertEquals(i, myStack.pop());
}
// 스택이 비어있는 상태에서 pop을 호출하면 -1을 반환한다.
assertEquals(-1, myStack.pop());
assertEquals(-1, myStack.pop());
}
}

과제4 : 앞서 만든 ListNode를 사용해서 Stack을 구현하세요.
- ListNode head를 가지고 있는 ListNodeStack 클래스를 구현하세요.
- void push(int data)를 구현하세요.
- int pop()을 구현하세요.
ListNodeStack 타입의 변수를 생성하면 내부에서 ListNode를 사용하고
push를 하면 마지막 위치에 노드를 삽입
pop을 하면 마지막 위치의 노드를 삭제하고 반환 하도록 했다.
package me.xxxelppa.study.week04;
public class ListNodeStack {
ListNode head;
public ListNodeStack() {
head = new ListNode();
}
public ListNodeStack(int data) {
this();
head.add(head, new ListNode(data), head.size());
}
public void push(int data) {
head.add(head, new ListNode(data), head.size());
}
/*
* 반환할 데이터가 없는 경우 -1 반환
*/
public int pop() {
try {
return head.remove(head, head.size()).getData();
} catch (NullPointerException e) {
return -1;
}
}
}
간단하게 작성해본 테스트 코드
package me.xxxelppa.study.week04;
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.*;
class ListNodeStackTest {
@Test
void pushTest() {
// 길이 0 인 스택 생성
ListNodeStack emptyListNodeStack = new ListNodeStack();
emptyListNodeStack.push(10);
assertEquals(10, emptyListNodeStack.pop());
// 길이 1인 스택 생성
ListNodeStack listNodeStack = new ListNodeStack(100);
assertEquals(100, listNodeStack.pop());
}
@Test
void popTest() {
// 길이 1인 스택 생성
ListNodeStack listNodeStack = new ListNodeStack(1000);
assertEquals(1000, listNodeStack.pop());
// 길이 0인 상태에서 pop 을 시도하면 -1 을 반환
assertEquals(-1,listNodeStack.pop());
}
}

과제5 : Queue를 구현하세요.
- 배열을 사용해서 한번
- ListNode를 사용해서 한번.
Queue는 FIFO (First In First Out) 로 동작하는 자료구조 이다.
외나무다리를 건넌다고 생각하면 될 것 같다.
배열로 구현하는게 조금 고민이다.
ListNode를 사용할 경우 0번째를 제거하고 마지막에 값을 추가하는 것으로 구현할 수 있다.
배열은 인덱스가 가장 작은 값을 반환하고, 가장 마지막 위치에 넣으면 되는데
문제는 배열로 만든 큐에서 값을 꺼내면 값이 하나씩 앞으로 당겨와야하는 갱신 작업이 필요하다.
값을 뺄 때마다 갱신하는 작업을 할지, 아니면 갱신 하지 않고 배열 크기를 무한정 늘리면서 참조하는 인덱스 값만 조정할지..
아무래도 크기를 정해 놓고, 일정 횟수 이상 값을 뺐을 경우 재 정렬 하도록 하는 것이 나을 것 같다.
우선 배열을 사용해서 구현해 보았다.
package me.xxxelppa.study.week04;
public class QueueUsingArray {
private final int EXTEND_SIZE = 10;
private int[] myQueue;
private int headPos;
private int tailPos;
public QueueUsingArray() {
this.myQueue = new int[EXTEND_SIZE];
this.headPos = 0;
this.tailPos = 0;
}
/*
* pop 실행 중 head 위치가 EXTEND_SIZE 에 다다르면 호출
* 배열의 0번째부터 값을 다시 채우고, headPos 와 tailPos 다시 할당
*/
public void resetQueue() {
for(int i = headPos, j = 0; i <= tailPos; ) myQueue[j++] = myQueue[i++];
tailPos -= headPos;
headPos = 0;
}
/*
* Queue 의 크기를 EXTEND_SIZE 만큼 확장
*/
public int[] extendQueue() {
int[] newQueue = new int[myQueue.length + EXTEND_SIZE];
for(int i = 0; i < myQueue.length; ++i) newQueue[i] = myQueue[i];
return newQueue;
}
// 배열의 마지막 위치에 값 추가
public void push(int data) {
if(tailPos + 1 == myQueue.length) myQueue = extendQueue();
this.myQueue[tailPos++] = data;
}
/*
* 반환할 데이터가 없는 경우 -1 반환
*/
public int pop() {
if(headPos == tailPos) return -1;
if(headPos > EXTEND_SIZE) resetQueue();
return myQueue[headPos++];
}
// Queue 에 들어있는 데이터의 수를 반환
public int size() {
return this.tailPos - this.headPos;
}
}
간단한 테스트 코드를 작성 해보았다.
package me.xxxelppa.study.week04;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.*;
class QueueUsingArrayTest {
QueueUsingArray queueUsingArray;
@BeforeEach
public void before() {
queueUsingArray = new QueueUsingArray();
queueUsingArray.push(10);
queueUsingArray.push(20);
queueUsingArray.push(30);
queueUsingArray.push(40);
queueUsingArray.push(50);
queueUsingArray.push(60);
queueUsingArray.push(70);
queueUsingArray.push(80);
queueUsingArray.push(90);
}
@Test
public void pushTest() {
assertEquals(9, queueUsingArray.size());
queueUsingArray.push(100);
queueUsingArray.push(110);
queueUsingArray.push(120);
// 기본 크기 10을 초과해도 자동으로 확장하여 데이터 입력이 가능
assertEquals(12, queueUsingArray.size());
}
@Test
public void popTest() {
// 들어있는 데이터 전부 소모
for(int i = 0; i < 9; ++i) {
queueUsingArray.pop();
}
// 더이상 데이터가 없는데 pop 을 시도하면 -1을 반환
assertEquals(0, queueUsingArray.size());
assertEquals(-1, queueUsingArray.pop());
}
}
지금 생각해보니 큐의 크기가 한 번 커지면 작아지지 않는다.
이런 것들을 포함해서 다양한 문제가 있지만.. 지금은 개념을 이해하는데 집중해서 간단하게 동작하는 정도로 구현하는 것에 만족..? 해야겠다.
마지막으로 ListNode 를 사용해서 Queue를 구현해본 코드이다.
package me.xxxelppa.study.week04;
public class QueueUsingListNode {
ListNode head;
public QueueUsingListNode() {
head = new ListNode();
}
public void push(int data) {
head.add(head, new ListNode(data), head.size());
}
public int pop() {
try {
return head.remove(head, 0).getData();
} catch (NullPointerException e) {
return -1;
}
}
}
ListNode를 사용하여 Stack을 구현했을 때와 거의 동일하다.
다른 점이 있다면, pop을 하여 데이터를 가져올 때 Stack 과 달리 선두에 있는 데이터를 가져온다는 것이다.
'Archive > Java online live study S01' 카테고리의 다른 글
| 6주차 : 상속 (0) | 2021.05.01 |
|---|---|
| 5주차 : 클래스 (0) | 2021.05.01 |
| 3주차 : 연산자 (0) | 2021.05.01 |
| 2주차 : 자바 데이터 타입, 변수 그리고 배열 (0) | 2021.05.01 |
| 1주차 : JVM은 무엇이며 자바 코드는 어떻게 실행하는 것인가 (0) | 2021.05.01 |